IConZIC (Image-Conditioned Zero-shot Image Captioning)
Proposed faster and stable caption generation utilizing Gibbs sampling and Masked VLM for zero-shot image captioning.
Contents
Introduction
Image Captioning (IC), the task of generating descriptive text for images, has traditionally relied on massive datasets of paired image-text examples (like MSCOCO). While effective, this supervised approach struggles with “outlier” images that deviate from the training distribution. This limitation has shifted research interest toward Zero-Shot Image Captioning (ZIC)—methods capable of captioning images without explicit pre-training on caption pairs.
In this post, I introduce IConZIC (Image-Conditioned Zero-shot Image Captioning), a project developed for the Korea University COSE461 Final Project. Our work builds upon existing state-of-the-art methods to address significant bottlenecks in initialization and generation efficiency.
The Problem: The “Blind” Initialization of ConZIC
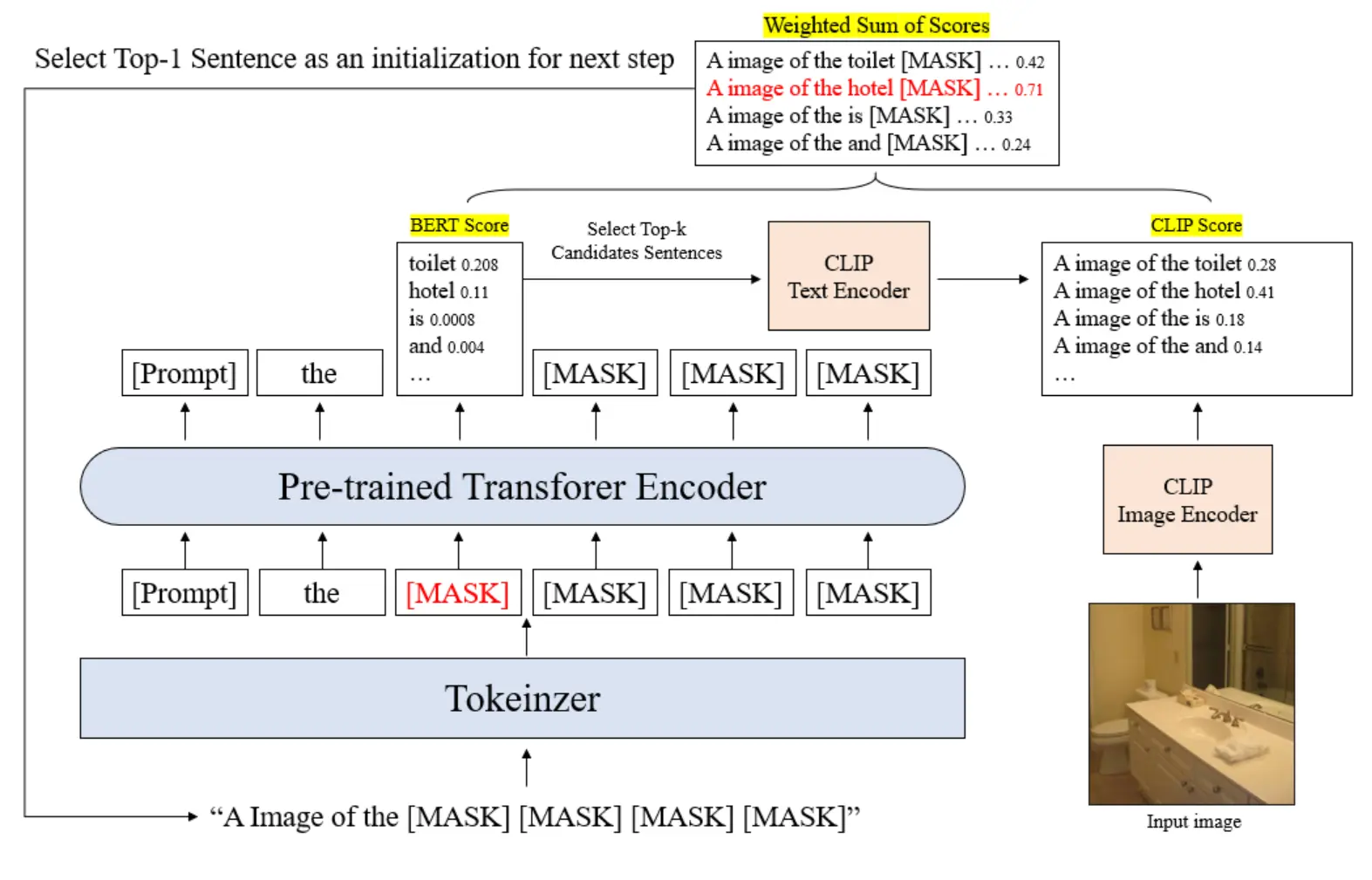
The starting point for our research was ConZIC, a leading zero-shot model. ConZIC operates by using a pre-trained Masked Language Model (MLM), specifically Gibbs-BERT, to generate caption candidates via iterative sampling.
However, we identified a fundamental structural inefficiency in ConZIC. Because BERT is a text-only model, it does not “see” the image during the candidate generation phase. It relies on random masks and requires a secondary CLIP model to filter the best options later.
This creates an initialization problem:
-
High Computational Cost: Since the initial candidates are blind to the visual context, the model must generate a large number of candidates (high value) to find relevant words.
-
Sensitivity: The model becomes highly sensitive to hyperparameter settings. Improper tuning often results in random word sequences or descriptions that ignore visual content.
The Solution: IConZIC and Gibbs-ViLT
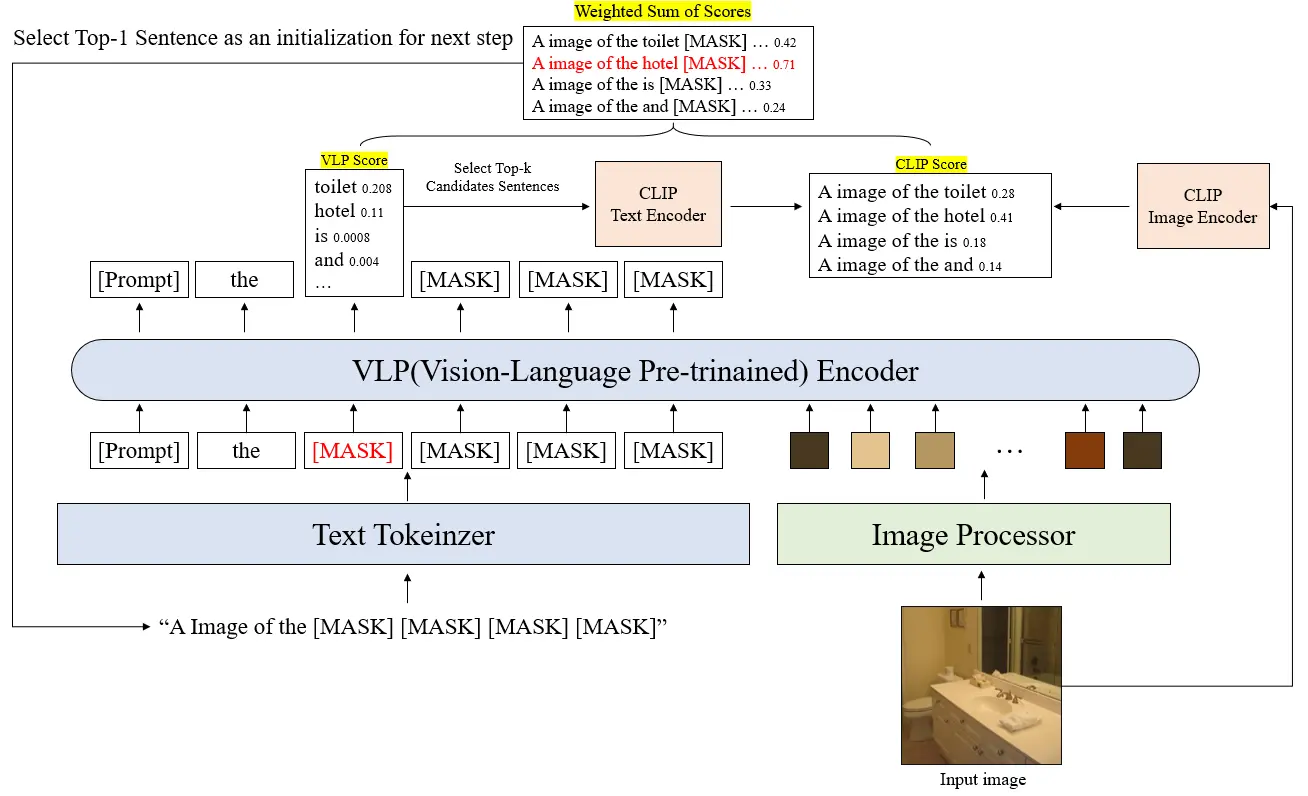
To solve the initialization problem, we proposed IConZIC. The core innovation lies in replacing the text-only Gibbs-BERT with Gibbs-ViLT, a sampling method utilizing a Vision-Language Pre-training (VLP) encoder.
Unlike BERT, ViLT is trained with an Image-Conditioned Masked Language Modeling (ICMLM) objective. This allows the model to predict masked tokens based on both textual context and visual tokens simultaneously.
How It Works:

-
Visual-Aware Sampling: Instead of starting with random guesses, IConZIC samples words from a distribution conditioned on the image from the very first step.
-
Refinement: We retained the CLIP-guided scoring mechanism to ensure high image-text alignment, selecting the best tokens based on a weighted sum of the ViLT probability and CLIP score.
This hypothesis was straightforward: if the model considers visual tokens from the start, we can generate accurate captions with significantly fewer candidates.
Experimental Results
We evaluated IConZIC against ConZIC using the MSCOCO validation set, focusing on accuracy (CLIPScore), diversity, and generation time.
1. Efficiency and Speed
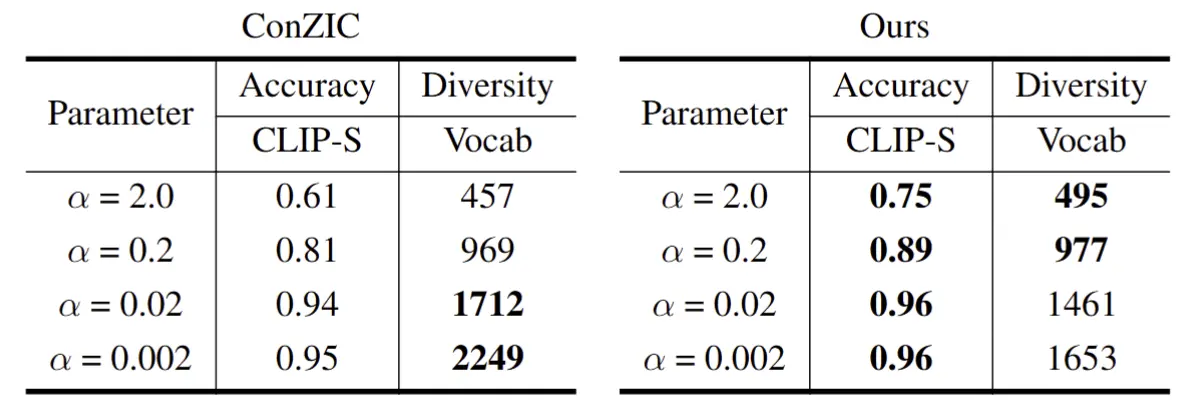
The most significant achievement was the reduction in computational cost. ConZIC typically requires a candidate size of to achieve optimal performance. In contrast, IConZIC achieved comparable accuracy with just **.
-
By reducing the search space, our model proved to be approximately four times faster in generation time while maintaining high quality.
-
Accuracy nearly converged at , demonstrating that ViLT performs significantly better than BERT in image-conditioned sampling.
2. Robustness
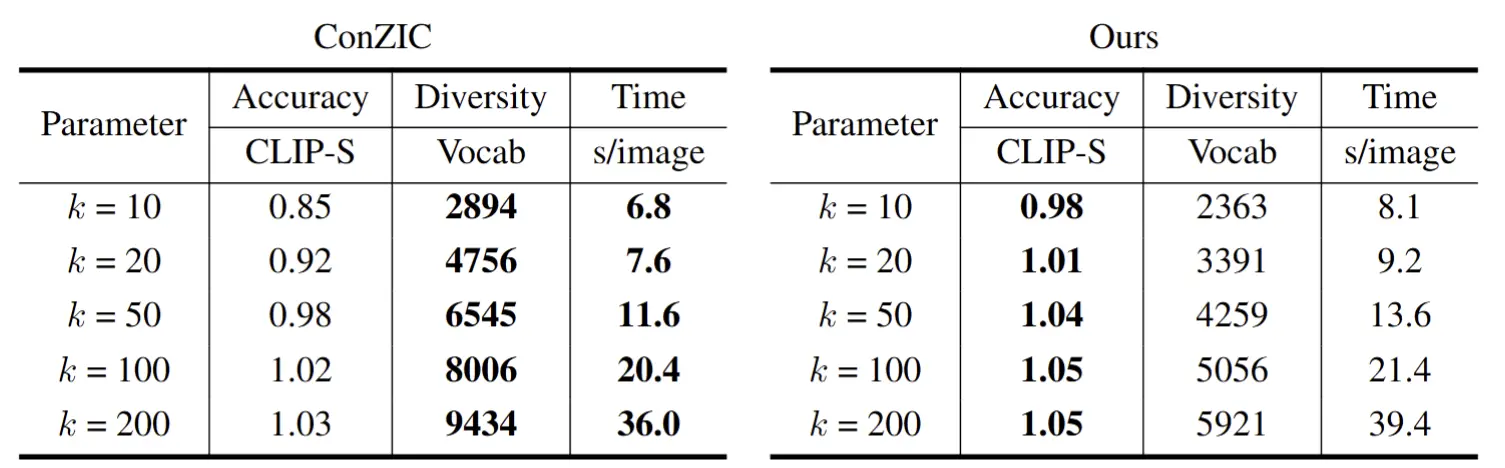
IConZIC demonstrated superior stability across different hyperparameter settings. Even with extreme values for the weighting parameter (e.g., ), where ConZIC’s performance collapsed, our model maintained decent accuracy.
3. Qualitative Performance on Out-of-Distribution Data

We tested the model on images that differ significantly from standard photo datasets, such as Minecraft screenshots, anime art, and line drawings. While ConZIC often failed to capture key elements or generated hallucinations in these scenarios, IConZIC consistently produced relevant and grounded captions.
Limitations and Trade-offs
It is important to note the trade-offs involved in this approach. Our experiments showed that IConZIC exhibits lower vocabulary diversity compared to ConZIC. This is attributed to the pre-training data: BERT is trained on vast, diverse internet text, whereas ViLT is trained on curated, human-annotated caption datasets. While this results in less varied vocabulary, the trade-off yields higher accuracy and relevance to the image content.
Conclusion
The IConZIC project demonstrates that ICMLMs can not only “see” but also “speak”. By integrating visual conditioning into the generative sampling process, we successfully resolved the initialization bottlenecks of previous zero-shot methods. This work highlights the potential of Vision-Language Pre-training models to create more efficient, robust, and accurate image captioning systems without the need for extensive supervised fine-tuning.