Revisiting Flow-Conditioned Motion Transfer via Pseudo-Flow and Consecutive Local Attention
A novel framework that redefines motion guidance in video diffusion by extracting 'pseudo-flow' from 2D attention layers, enabling more interpretable and robust motion transfer.
Introduction
In video generation, motion is not merely a visual change but a form of structural consistency that must be preserved over time for scenes and objects. Frame-level realism alone is insufficient; object positions, shape continuity, and the direction and magnitude of movement must remain logically connected across time. As a result, video generation presents far more complex constraints than image generation.
Early approaches addressed this challenge by conditioning generation on explicit motion representations such as optical flow, human pose, or tracking information. While effective in domains with well-defined structures, these methods struggled to generalize to generic objects or complex scenes, where defining motion itself becomes difficult. Estimating stable flows or poses for non-parametric objects is inherently challenging.
Motion transfer emerged as an alternative paradigm. Instead of injecting explicit motion conditions, motion transfer methods extract movement information from a source video and apply it to a target. This expands applicability across domains, but at the cost of interpretability: it becomes unclear how motion is represented or preserved, and many approaches rely heavily on model-specific or heuristic designs.
This work revisits flow-based perspectives within modern diffusion architectures. We ask whether flow-like representations can be extracted from a diffusion model’s internal attention structure without external motion definitions, and whether such representations can be used in a stable and architecture-agnostic manner.
Motivation
This study originated from a detailed analysis of Diffusion Motion Transfer (DMT). DMT attracted attention by preserving motion during sampling while keeping a pre-trained text-to-video diffusion model fixed. Notably, it avoids external motion estimators by defining motion through internal spatio-temporal features of the model.
However, through close examination and practical use, two concerns became apparent.
The first concerns evaluation. It was unclear whether existing benchmarks and metrics for motion transfer truly aligned with human judgment or visual quality. This concern motivated the ReMoTE benchmark, which systematically analyzes the limitations and reliability issues of existing motion metrics.
The second concern lies within the methodology itself. DMT’s core mechanism—preserving residuals of space-time features—is intuitive, yet strongly heuristic. Whether global feature differences genuinely represent motion, and how sensitive this definition is to layer choice or architecture, remained open questions.
This paper addresses the second concern. We build upon DMT’s framework while exploring whether motion can be defined in a more interpretable and structurally explicit form.
DMT
DMT begins with the assumption that motion information is already embedded in the spatio-temporal representations learned by diffusion models. This allows motion preservation without learning new representations or injecting external conditions.
An input video is first inverted into a latent diffusion trajectory using DDIM inversion. At each timestep, the latent passes through intermediate layers of the diffusion model, producing spatio-temporal features spanning both frame and spatial dimensions. These features encode appearance, spatial layout, and temporal change.
Because appearance and motion are entangled, DMT applies spatial averaging to produce a global feature per frame. This operation suppresses fine-grained appearance details while emphasizing structural changes over time.
Directly matching global features, however, overly constrains appearance. To mitigate this, DMT introduces a loss based on frame-to-frame residuals rather than absolute feature values. This loss encourages the generated video to follow the same temporal variation pattern as the reference while allowing appearance changes.
Additionally, DMT initializes sampling by preserving only the low-frequency components of the input video and replacing high-frequency components with random noise. This strategy balances motion preservation with editability.
Overall, DMT operates by inserting optimization steps into the diffusion sampling process, iteratively aligning motion-related feature statistics.
Limitations
Despite its contributions, DMT exhibits several structural limitations.
The primary issue is how motion is defined. Frame-wise differences of global features are easy to compute but do not directly represent spatial displacement or correspondence. As a result, the motion representation lacks interpretability and may vary significantly depending on feature selection.
Furthermore, defining motion as a statistical difference weakens its connection to physical intuition, such as optical flow. This makes analysis and failure diagnosis more difficult.
Finally, some subsequent approaches rely on 3D or spatio-temporal attention mechanisms to extract motion signals. However, many widely used diffusion models still rely on 2D or factorized attention, limiting the general applicability of such assumptions.
Method
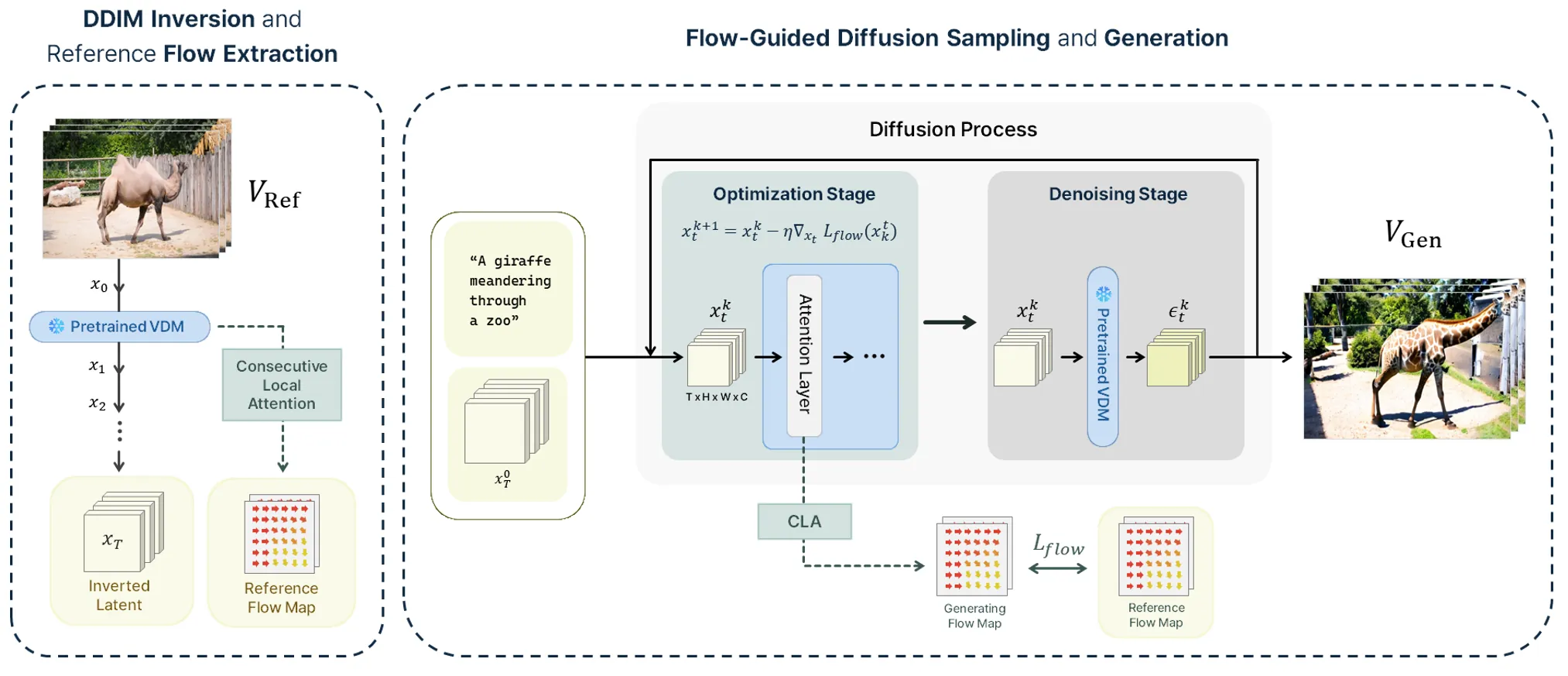
To address these limitations, we propose extracting pseudo-flow representations that explicitly encode frame-to-frame displacement. The key insight is that even in 2D self-attention architectures without explicit temporal interaction, flow-like information can be induced through minimal structural modification.
We introduce temporal token shifting, which reconfigures attention computation so that queries from one frame attend to keys from the subsequent frame. This transforms attention scores into indicators of inter-frame correspondence.
Because attention naturally allows long-range interactions, this alone leads to noisy or diffuse correspondences. To counter this, we apply a local correspondence constraint, restricting attention to spatially nearby tokens and reflecting the physical assumption of limited inter-frame displacement.
Using these constrained attention weights, we compute expected target coordinates for each position and derive displacement vectors relative to original positions. This displacement field constitutes the proposed pseudo-flow, enabling direct and interpretable motion representation.
Sampling
Once pseudo-flow is defined, it can be used to guide diffusion sampling. Pseudo-flow is extracted from a reference video using the same mechanism, and a loss is defined between the reference flow and the flow computed from the generated video.
At each diffusion step, the latent is updated through a small number of gradient descent steps to minimize this flow alignment loss, followed by the standard denoising update. This mirrors DMT’s optimization-based sampling structure but replaces feature residual alignment with direct flow alignment.
Empirically, we find that short DDIM inversion schedules suffice for stable appearance editing, significantly improving computational efficiency.
Experiments
Evaluation is conducted using the ReMoTE benchmark. Compared with existing motion transfer methods, the proposed approach demonstrates strong motion alignment and structural consistency, particularly in intra-category settings.
Visual inspection further confirms that the local correspondence constraint substantially reduces background noise in pseudo-flow maps and yields clearer object motion, highlighting the importance of locality in flow extraction.
Conclusion
This work revisits how motion should be defined and utilized in diffusion-based motion transfer. Building upon DMT’s framework, we redefine motion as an explicit displacement field rather than a statistical feature difference, while maintaining compatibility with 2D attention architectures.
Evaluation reliability is addressed through ReMoTE, and methodological limitations are tackled via CLA-based pseudo-flow extraction. Together, these efforts contribute toward more interpretable and generalizable motion transfer frameworks. Future work will focus on improving generalization in cross-category transfer scenarios.