Repurposing Geometric Foundation Models for Multi-view Diffusion
Repurposing Geometric Foundation Models for Multi-view Diffusion
Contents
Abstract
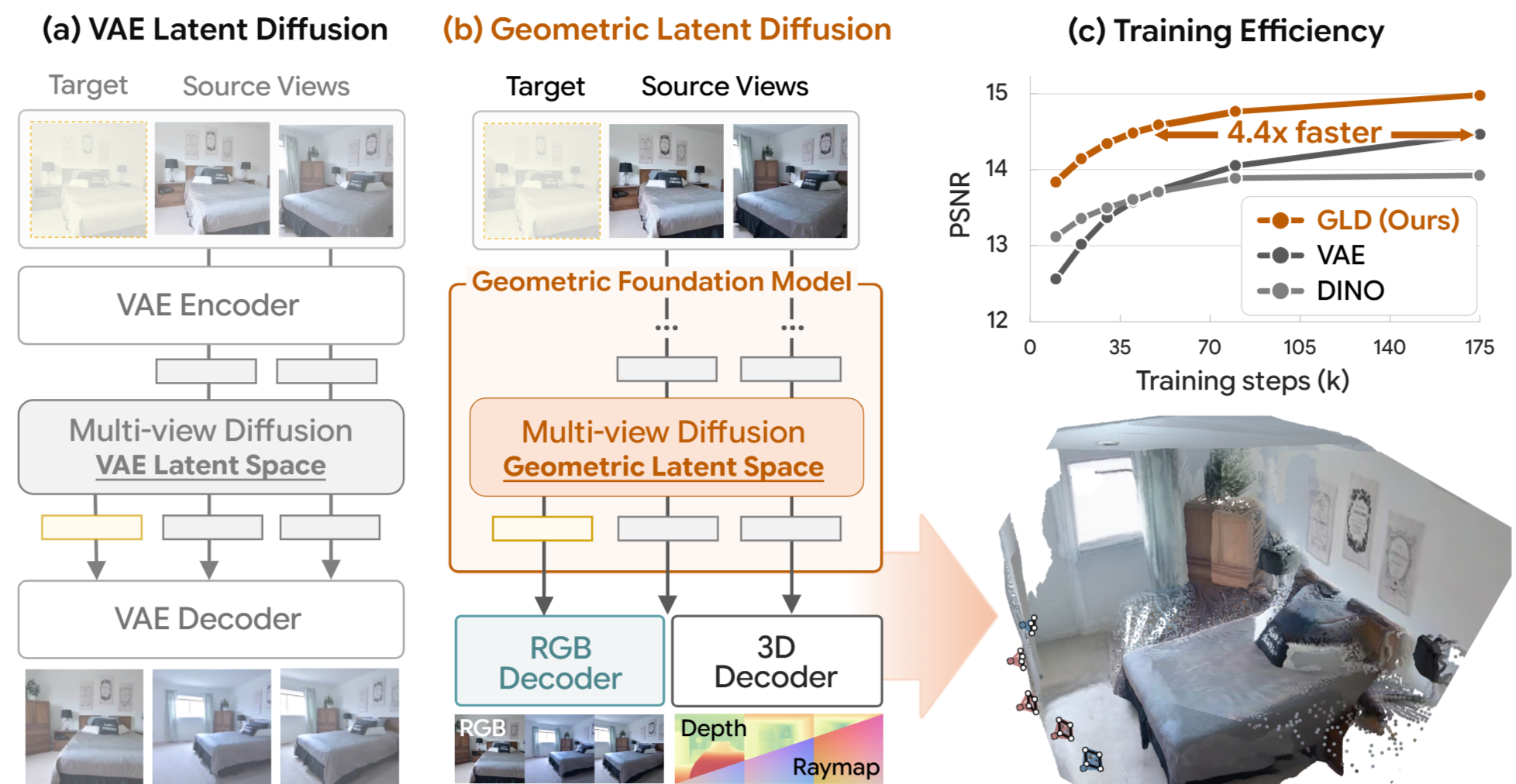
Latent diffusion models have achieved remarkable success in multi-view image generation by encoding images into a compact latent space using a pretrained Variational Autoencoder (VAE). However, despite their effectiveness in image compression, VAE features are not inherently designed for 3D tasks, potentially limiting performance in multi-view generation. In this work, we propose Geometric Latent Diffusion (GLD), which repurposes the feature space of geometric foundation models as the latent representation for multi-view diffusion. Our approach achieves 4.4× faster training convergence compared to VAE-based approaches and delivers competitive performance with methods that leverage text-to-image pretraining, despite being trained from scratch. Furthermore, the frozen geometric decoder enables zero-shot geometry decoding, allowing direct depth estimation and point cloud generation from the diffusion output without additional training.