Publication
Geometric Action Model for Visuomotor Control
An under-review geometry-aware action modeling approach for visuomotor control.
Under Review, 2026
Research, side projects, and selected publications. Tap a tag to narrow the grid.
An under-review geometry-aware action modeling approach for visuomotor control.
Under Review, 2026
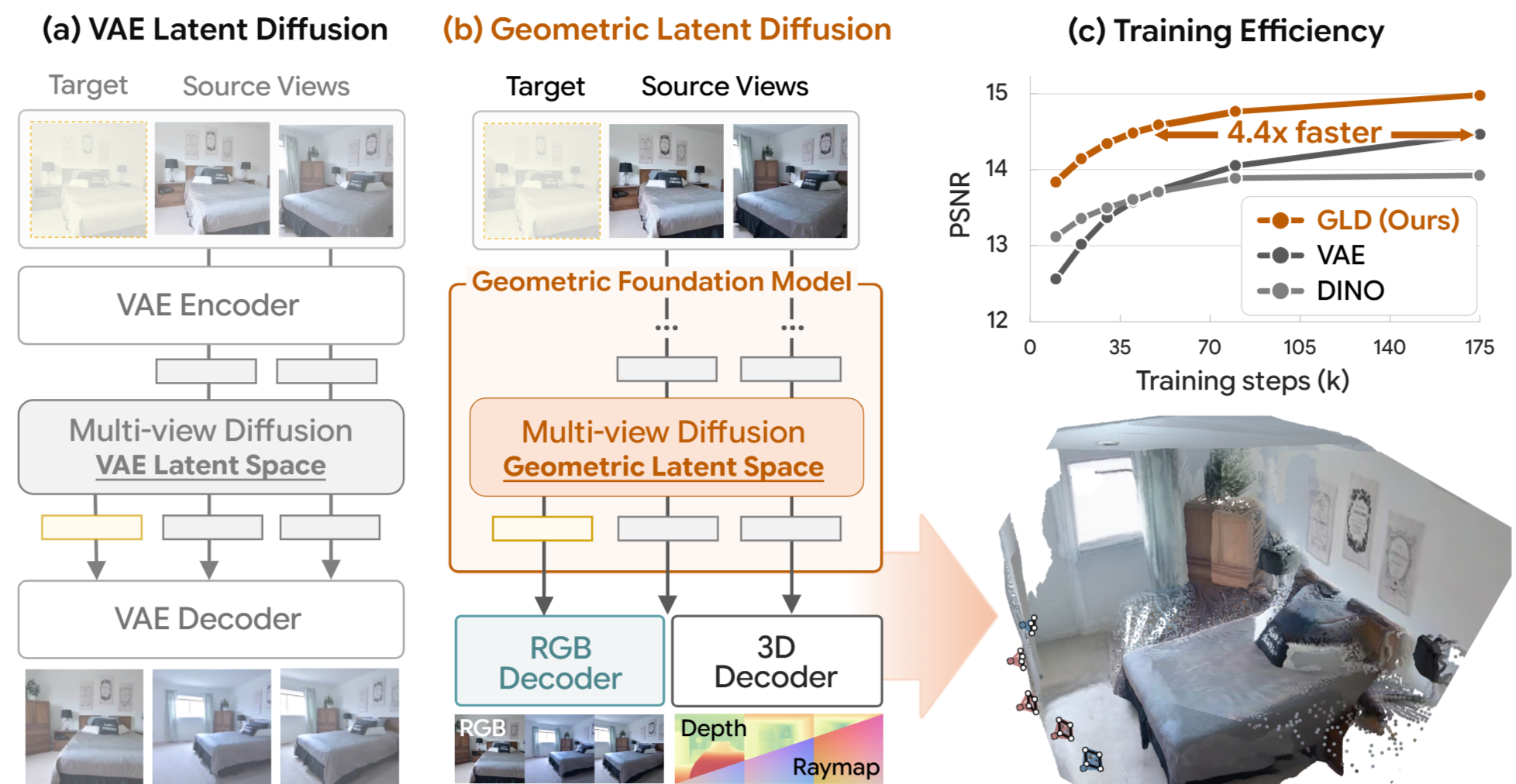 Publication
Publication
We repurpose geometric foundation model features as latent space for multi-view diffusion, achieving 4.4× faster training convergence and zero-shot geometry decoding.
Under Review, 2026
A visual builder for creating academic research project pages — drag-and-drop sections, multiple templates, LLM-powered paper extraction, and one-click GitHub deployment.
 Publication
Publication
A training technique that supervises attention maps using geometric correspondence, reducing training iterations by half while achieving superior multi-view generation quality.
CVPR 2026
 Publication
Publication
A method that learns condition-dependent source distributions for flow matching, enabling straighter transport paths and up to 3x faster convergence.
Under Review, 2026
A practical study on improving semantic segmentation for autonomous driving under limited data and compute, focusing on architecture choices, coordinate-aware convolutions, and optimizer/schedule tuning.
AIKU (Korea University AI Society) Internal Project
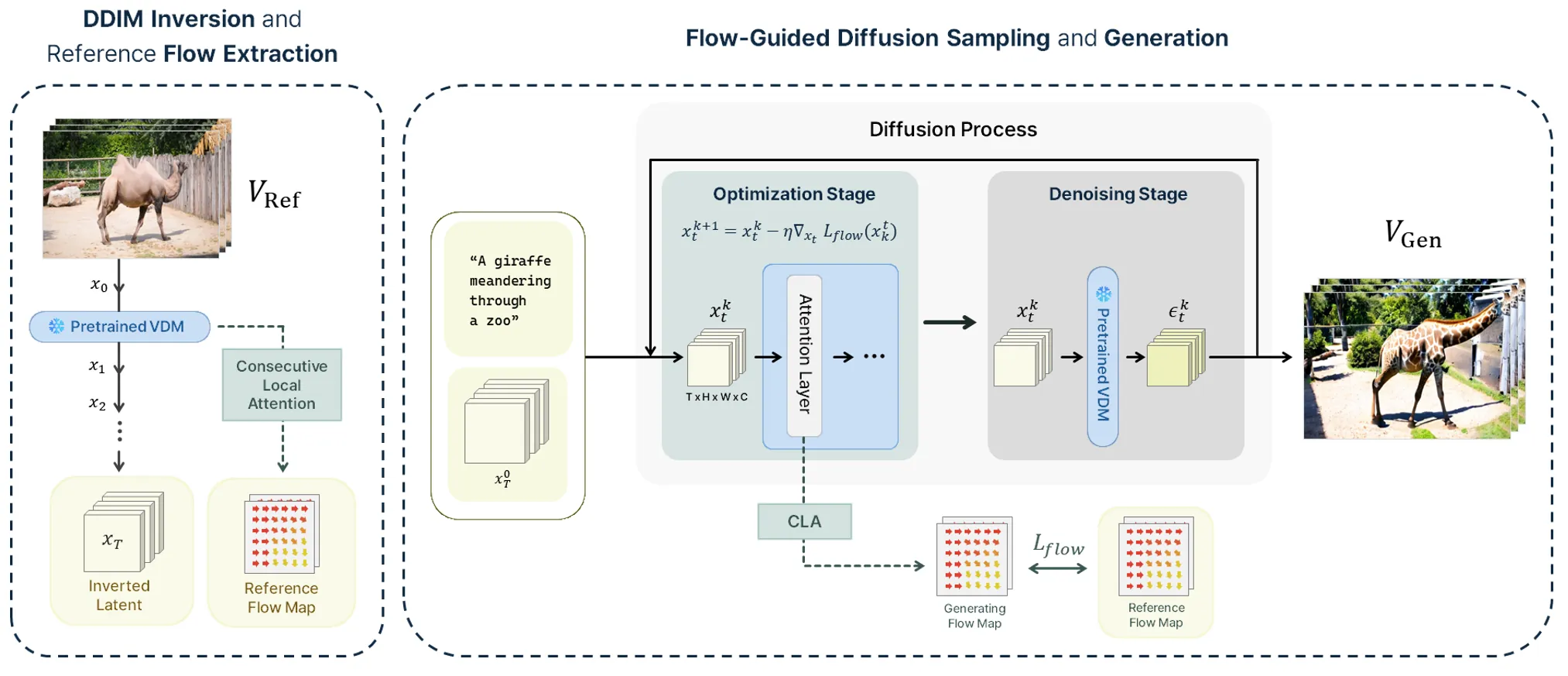
A novel framework that redefines motion guidance in video diffusion by extracting 'pseudo-flow' from 2D attention layers, enabling more interpretable and robust motion transfer.
IEIE 2025 Undergraduate Paper Competition (Excellence Award)
 Publication
Publication
A benchmark dataset and evaluation protocol for object motion transfer, introducing improved metrics that better correlate with human perception.
ITC-CSCC 2025 (Oral)
Finetuned semantic map-conditioned LDMs with ControlNet for unsupervised and unpaired Synthetic-to-Real image translation.

AI profile picture generation service for Korea University festival — identity-preserving Stable Diffusion pipeline serving 2,000+ students.
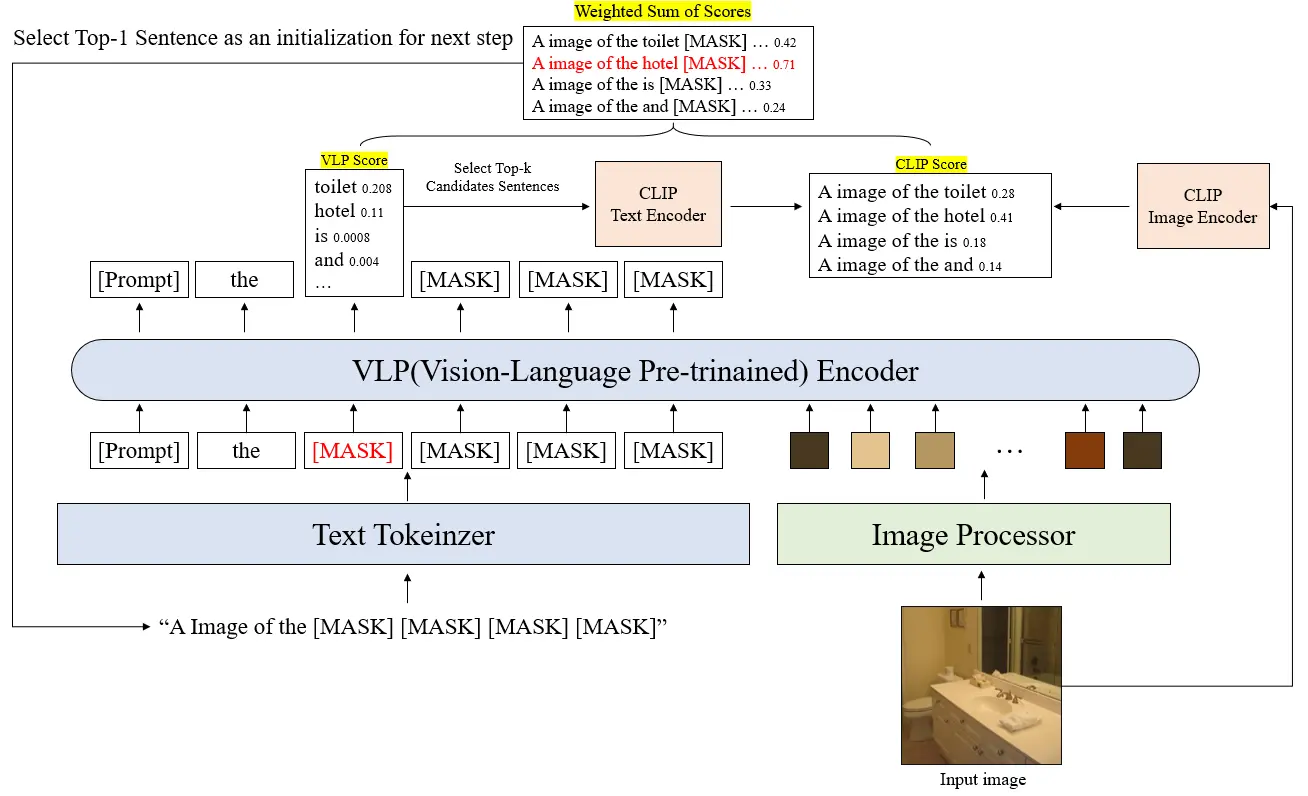
Proposed faster and stable caption generation utilizing Gibbs sampling and Masked VLM for zero-shot image captioning.
Music recommendation service using VLM and LLM-based lyrics augmentation to match user preferences and context.